Graham Mitchell
CS 378 Networks
The internet is a busy place. Several years ago, domain name mapping updates from a few ftp sites constituted the largest threat to bandwidth and a single server with a moderate connection could easily handle all service requests. With the exponential increase in the popularity of more bandwidth-intensive applications, especially the World-Wide Web, popular servers are finding it hard to keep up. For example, Starwave corporation, which hosts www.nba.com, now runs a five-node SPARC-center 1000 just to keep up with demand.
Part of the problem lies in the fundamental design of the internet. Either in an effort to rush protocols out the door or because software developers (unlike network administrators) perceive bandwidth as virtually unlimited, most existing internet information services were designed without inherent support for caching. As a result, FTP and HTTP servers find themselves swamped with requests for the same popular files, like the demand for images of the Shoemaker-Levy 9 comet which saturated NASA's Jet Propulsion Laboratory's wide-area network links in July 1994. As a result, there has been an attempt to retrofit caches for internet information system servers like the popular CERN proxy-http cache. One recently developed cache which deserves further examination is the Harvest cache, which boasts improved performance of an order of magnitude over the CERN cache and even over popular http daemons like Netscape's Netsite and NCSA's 1.4 httpd.
The Harvest cache is a heirarchical "internet object" proxy-cache developed jointly by researchers at USC and the University of Colorado in Boulder in the latter part of 1995. Supporting near transparency for clients and a highly scaleable architecture, the Harvest cache is useful as a stand-alone single cache or as a load-balanced heirarchical cache with any useful spanning topology desired. First let us examine how a web provider would use the Harvest cache as an httpd-accelerator to reduce load on a busy system.
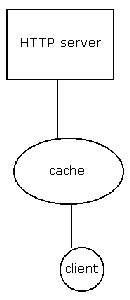
Ideally, the Harvest cache software is run on a dedicated server with a high-bandwidth internet connection, a substantial amount of RAM (60-80 MB to cache one million objects), and several large, fast hard drives. The cache machine listens to port 80 and is connected to the site's real httpd server, which resides on port 81. This configuration is shown at right. Incoming requests are served from the cache if found. For a miss or request for a non-cacheable object, the cache requests the appropriate file from the server and forwards it to the original requestor while simultaneously adding it to the cache. On a cache hit, the Harvest httpd-accelerator serves documents with a median response time of 20 milliseconds, versus 300 ms for both Netscape's Netsite and NCSA's 1.4 httpd. And on a miss, the Harvest cache adds only about 20 ms to the real httpd server's access time.
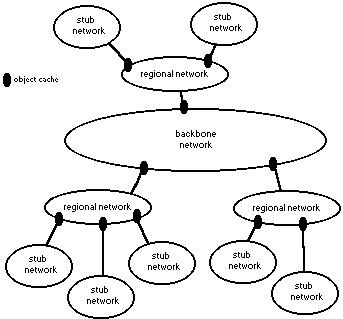
Although the Harvest cache performs exceedingly well as a httpd-accelerator, it is when the cache is used as a node in a heirarchical cache topology that the differences between the Harvest cache and standard caches can be seen. In such a setup, the cache is only one of many caches on a particular network, and the individual caches can be interconnected heirarchically to reflect that network's topology (below). In addition to a parent-child relationship, each cache supports a notion of siblings at the same level who aid in load distribution.
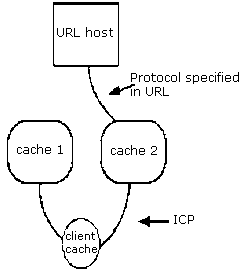
When a requested object is found within the cache, the caching machine simply responds with the requested data in the same manner as the httpd-accelerator case. If the object is considered non-cacheable (as specified by a configurable list of substrings), the cache ignores any cache heirarchy and fetches the object directly from the object's home. Or, if the URL's domain name matches a configurable list of substrings, the object is resolved though the parent cache logically associated with that domain.
When the object is not within the cache, and does not match any special substring, the cache "performs a remote procedure call to all of its siblings and parents, checking if the URL hits any sibling or parent. The cache retrieves the object from the site with the lowest measured latency."
For the resolution protocol, the cache does not simply forward the HTTP GET request to all its siblings and parents, returning the object received most quickly. This method, though simple, would probably increase the load on the original server and certainly chew up bandwidth with multiple copies of an object returned, most of which would be discarded.
Instead, for intercommunication, caches implement the Internet Cache Protocol (ICP), currently in version 1.4. This is a simple UDP-based protocol which uses just nine different messages to resolve hits and send replies among related caches. Each ICP packet contains a 16-byte header containing six fields including an opcode, packet length, request number (for multiplexing) and even authentication information (for future use).
Initially, the cache will send an ICP Query message to all neighboring caches. This message consists of the standard header (with an opcode of 1) and two additional fields: requester and url. Typically, it is sent in a single UDP datagram to each related node in the heirarchy to see if any have the object in their cache. The requester field is used to identify the ultimate destination of the response.
A cache will reply to a query message with either an ICP Hit message or a Miss message (or an Error message in case of an error). The hit and miss packets are identical (except for their opcodes: 2 and 3 respectively), consisting of only the common header and a single variable length field containing the URL checked.
Once replies begin arriving at the cache that issued the query, it resolves the request through the first sibling or parent to return an ICP Hit message, or through the first parent to return an ICP Miss if all caches miss. Additionally, the referenced URL's home site can be "tricked" into implementing the resolution protocol: when the cache sends out its ICP Queries, it also sends an ICP Hit message to the UDP echo port of the home site. Thus, if the home site is 'closer' than any of the caches, its hit reply will be recieved first, and the cache will resolve the object through the home site. The cache does not, however, wait for the home site to time out; it sends the request for the object as soon as all other caches have responded. Thus the cache will resolve the request through the source that can provide it most efficiently.
Due to the small size of the ICP messages, and the Harvest cache's low response time, heirarchies even three layers deep do not add measurably to latency. Testing indicates that even under a 0% hit workload, each layer adds only 4-10 milliseconds of latency, clearly an acceptable tradeoff for the load distribution which a heirarchical cache can provide.
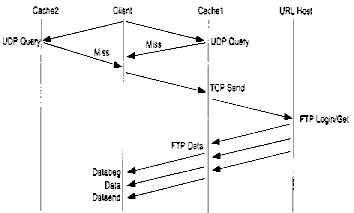
Once the client cache (the cache for whom the original request missed) has determined the source it will use to resolve the reference, it sends an ICP Send message to this source. This has a format identical to the ICP Query and requests that the specified object be sent as a reply.
The "server" cache will typically respond with an ICP Data Begin message, which consists of the common header, a size field, time-to-live, a timestamp and the first segment of data from the object. This serves both to notify the client cache of the coming requested object and to begin sending the actual contents. For small objects, it is quite possible that the entire object will be sent in the data portion of the Data Begin message, avoiding the need for the establishment of a separate TCP connection.
The rest of the object is sent with several ICP Data messages, which consist simply of the common header, an offset into the object, and the data. The last part of the object is sent with the ICP Data End message, which is identical to the Data message save the opcode. For small messages, the Data End message contains no data, since it was all sent in the original ICP Data Begin, and serves only to mark the end of the object.
Once the client cache begin receiving the data of the referenced file, "these bytes are simultaneously forwarded to all sites that referenced the same object and are written to disk, using non-blocking I/O" and multithreading. In this way, all interested parties receive the file as soon as possible and the intial request has finally been filled. The trace of messages is shown below.
At this point, some of the more interesting internal design elements of the Harvest cache can shed some light on its high performance. Memory management is described as follows:
It keeps all meta-data for cached objects ( URL, TTL, reference counts, disk file reference, and various flags) in virtual memory. This consumes 48 bytes + strlen(URL) per object on machines with 32-bit words.
This allows fast hash lookup of existing objects (using a hash table keyed by URL), and it should become even faster when the variable length URLs are replaced with a fixed length MD5, reducing memory storage to a mere 60 bytes per object. In addition, exceptionally hot objects can be kept in memory if the cache is being used as a httpd-accelerator. Hot objects are removed from memory using LRU.
The cache is write-through to minimize page faults, so that even hot objects also have a disk image. Objects in the cache are stored among multiple disks: the cache manages them "and attempts to balance load among them. It creates 100 numbered directories on each disk and then rotates object creation among the disks and directories."
Keeping all the object meta-data in RAM, the use of a hot object RAM cache, and threading (for non-blocking disk I/O) allows the Harvest cache to boast a roughly 260 ms difference in median response time over the CERN httpd and results in a factor of ten improvement in overall performance. Perhaps the Harvest cache, with its heirarchical design so well-suited to internet information systems, can help save overloaded servers and make the internet a faster place to live.
The Harvest cache can be freely downloaded pre-compiled for a variety of operating systems, including SunOS, Solaris, DEC OSF-1, HP-UX, SGI, Linux, and IBM AIX or in source form for porting to other operating systems.
"A Heirarchical Internet Object Cache"
Chankhunthod, Danzig, Neerdaels - CS Dept. USC
Schwartz, Worrell, - CS Dept. UColorado - Boulder
All diagrams are reworkings of those found in this paper.
"The Internet Cache Protocol Specification 1.4"
The message trace diagram is taken from this document.
"The Simple Internet Cache Protocol Specification"
No diagrams were taken from here.